
We've been talking about end-to-end IP production for some time now, and it's finally becoming reality. Manufacturers are getting on board, IBC had an IP showcase and 91�ȱ� Wales are getting an IP core. Our Lightweight Live demo at IBC 2017 also showed what IP Production could look like in the cloud, taking R&D's previous IP Studio work and running it in AWS. Now we're starting to think about what truly "cloud-fit" production might look like.

We think this means breaking our flows of media down into small objects, such as a frame of video or a frame’s worth of audio. These objects are then stored in an object store with their identity, timestamp and other metadata. We can process objects in parallel, and even use serverless computing such as AWS Lambda. This opens up opportunities for flexible production, discussed in more detail on the . However to begin with we need to find a way to store our objects; and we’ve been experimenting with the .
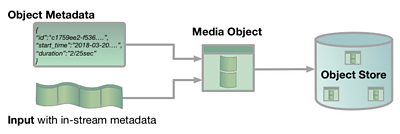
Our Media Object Experiments
The 91�ȱ� already uses S3 as a media object store in our online distribution pipeline. Chunks of video are taken from our broadcast encoders and uploaded while a programme is being broadcast. When the programme ends, the chunks are then extracted and encoded for distribution on iPlayer - the 91�ȱ�'s Lead Architect Stephen Godwin talked about this in his .
We wanted to know whether we could upload objects fast enough to cope with real-time uncompressed HD video streams. To try it we built some simple test software to upload objects filled with random data from several cloud compute instances; simulating uploading real media objects. The software recorded the start and end time of each object upload, which were used to calculate average upload rate. Various automation scripts meant the cloud compute instances could be started up, configured, used to run tests and shut down again; with no user input required.
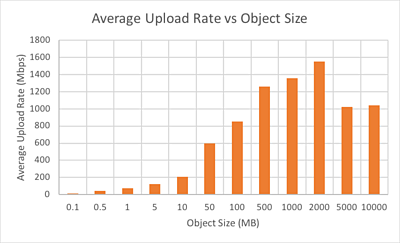
We found objects needed to be fairly large (of the order of 500MB to 2GB) to get upload rates good enough for real time uncompressed video, and that object size was the largest driver of upload speed. However larger objects come with a penalty, in that it takes longer for them to form in real-time. For example, if one object is the equivalent of five seconds of video, it takes at least five seconds before the object can be uploaded. If we combine this with how long it takes the object to upload, we can find the latency – how long it is between an object’s first frame arriving, and it being available in the store. Smaller objects mean latency can be reduced.
Parallelism
We need an upload rate of around 750Mbps for the smallest uncompressed video format we work with (HD 8-bit), and that increases to 1.5Gbps for “production quality” (HD 10-bit padded). Looking at the graph, that means using 2GB objects and having no margin for variation in S3’s performance. However there is another way; we can run multiple compute instances uploading in parallel and combine their upload rates.
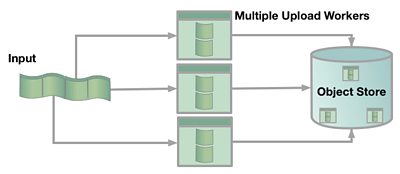
This gives us some flexibility; we can choose to reduce the latency by adding more instances, but we’ll have to pay more for running the servers.
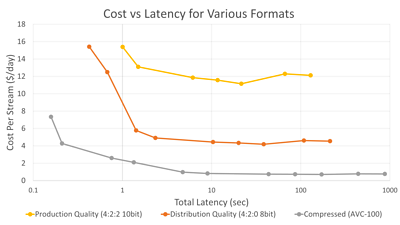
This cost-vs-latency tradeoff is one of the key design parameters of our storage system, and is plotted for various object sizes and video formats below.
Scability
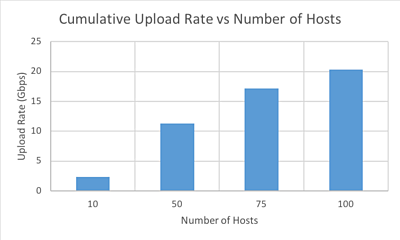
Another area of interest is in scalability; how many video streams can we add before S3 starts to slow down? To test this, we steadily increased the number of EC2 compute instances writing into S3 up to 100. Looking at the per-host average upload rate, it doesn’t really change as the number of instances increases. If we plot cumulative upload rate across all hosts, it increases steadily with the number of hosts. This trend continued up to 20Gbps for our 100 host maximum.
We took a brief look at some of the other parameters we can adjust in our client software (which uses the library), and found that the default settings mostly provide the best performance. We also tested various EC2 instance types, and the “c5.large” has by far the best performance for the price with our use case.
What Next
Now that we’ve proved our idea is actually possible, the next step is to make a prototype. That means building something to manage the metadata for our objects; which flow they belong to and the time range they represent. We also plan to make our object store immutable; once an object is written it cannot be updated. This means we have to implement in our metadata management, but means we can achieve our stored by default workflow.
We’ll use the prototype to validate some of our tests with real media content, and continue to build the other components of our system. We’ll also carry out read tests to check we can get the objects back out again. We'll also use these experiments to inform the design of our experimental on-premise cloud.
- Part 2 of this series looks at read tests, and some other object store options.
- Sign up for the IP Studio Insider Newsletter:
- Join our mailing list and receive news and updates from our IP Studio team every quarter. Privacy Notice
- First Name:
- Last Name:
- Company:
- Email:
- or Unsubscribe
- -
- 91�ȱ� R&D - High Speed Networking: Open Sourcing our Kernel Bypass Work
- 91�ȱ� R&D - Beyond Streams and Files - Storing Frames in the Cloud
- 91�ȱ� R&D - IP Studio
- 91�ȱ� R&D - IP Studio: Lightweight Live
- 91�ȱ� R&D - IP Studio: 2017 in Review - 2016 in Review
- 91�ȱ� R&D - IP Studio Update: Partners and Video Production in the Cloud
- 91�ȱ� R&D - Running an IP Studio
- 91�ȱ� R&D - Building a Live Television Video Mixing Application for the Browser
- 91�ȱ� R&D - Nearly Live Production
- 91�ȱ� R&D - Discovery and Registration in IP Studio
- 91�ȱ� R&D - Media Synchronisation in the IP Studio
- 91�ȱ� R&D - Industry Workshop on Professional Networked Media
- 91�ȱ� R&D - The IP Studio
- 91�ȱ� R&D - IP Studio at the UK Network Operators Forum
- 91�ȱ� R&D - Industry Workshop on Professional Networked Media
- 91�ȱ� R&D - Covering the Glasgow 2014 Commonwealth Games using IP Studio
- 91�ȱ� R&D - Investigating the IP future for 91�ȱ� Northern Ireland
Scability
Another area of interest is in scalability; how many video streams can we add before S3 starts to slow down? To test this, we steadily increased the number of EC2 compute instances writing into S3 up to 100. Looking at the per-host average upload rate, it doesn’t really change as the number of instances increases. If we plot cumulative upload rate across all hosts, it increases steadily with the number of hosts. This trend continued up to 20Gbps for our 100 host maximum.
We took a brief look at some of the other parameters we can adjust in our client software (which uses the library), and found that the default settings mostly provide the best performance. We also tested various EC2 instance types, and the “c5.large” has by far the best performance for the price with our use case.
What Next
Now that we’ve proved our idea is actually possible, the next step is to make a prototype. That means building something to manage the metadata for our objects; which flow they belong to and the time range they represent. We also plan to make our object store immutable; once an object is written it cannot be updated. This means we have to implement in our metadata management, but means we can achieve our stored by default workflow.
We’ll use the prototype to validate some of our tests with real media content, and continue to build the other components of our system. We’ll also carry out read tests to check we can get the objects back out again. We'll also use these experiments to inform the design of our experimental on-premise cloud.
- Part 2 of this series looks at read tests, and some other object store options.
- -
- 91�ȱ� R&D - High Speed Networking: Open Sourcing our Kernel Bypass Work
- 91�ȱ� R&D - Beyond Streams and Files - Storing Frames in the Cloud
- 91�ȱ� R&D - IP Studio
- 91�ȱ� R&D - IP Studio: Lightweight Live
- 91�ȱ� R&D - IP Studio: 2017 in Review - 2016 in Review
- 91�ȱ� R&D - IP Studio Update: Partners and Video Production in the Cloud
- 91�ȱ� R&D - Running an IP Studio
- 91�ȱ� R&D - Building a Live Television Video Mixing Application for the Browser
- 91�ȱ� R&D - Nearly Live Production
- 91�ȱ� R&D - Discovery and Registration in IP Studio
- 91�ȱ� R&D - Media Synchronisation in the IP Studio
- 91�ȱ� R&D - Industry Workshop on Professional Networked Media
- 91�ȱ� R&D - The IP Studio
- 91�ȱ� R&D - IP Studio at the UK Network Operators Forum
- 91�ȱ� R&D - Industry Workshop on Professional Networked Media
- 91�ȱ� R&D - Covering the Glasgow 2014 Commonwealth Games using IP Studio
- 91�ȱ� R&D - Investigating the IP future for 91�ȱ� Northern Ireland
-

Automated Production and Media Management section
This project is part of the Automated Production and Media Management section