
Image and video compression methods are the core technologies that enable digital broadcasting, streaming, as well as image and video sharing on social media.
Those compression methods have emerged over the last few decades from areas such as signal processing, algorithmic information theory and visual perception understanding. Building blocks of compression standards, such as JPEG, MPEG-2, H264/AVC and their successors, were carefully crafted by many experts around the globe.

Over the last five years, researchers have started rethinking compression as a computer vision problem, building new solutions with machine learning, particularly using versatile deep learning modules. In this way, image and video coding can be achieved using end-to-end neural network architectures. The main advantage of this approach is that pixels are first passed through neural network encoders to obtain content representation in a , which is then easier to compress. To achieve that, such encoders apply more complex nonlinear transforms, which have data-driven learned parameters that explicitly optimised to minimise rate and distortion in an end-to-end fashion.
What we are doing
So far, the field of neural image and video compression research has focused on improving compression and reducing memory and complexity requirements. However, since neural compression methods are completely different from traditional video codecs, this emerging approach provides an opportunity to experiment with new codec functionalities and rethink what is needed for the next generation of image and video codecs.

One of the key conceptual differences between traditional coding and neural network coding is that the codec architecture allows much more freedom when using neural codecs. Since both encoder and decoder models are learned (meaning they can be re-trained), the same encoder or decoder architecture can be specialised for different tasks. This can lead to better compression in situations where there is a distinct type or theme of content (i.e. a specific domain such as cityscapes, as in the picture below). It also implies that different applications can potentially customise a decoder in an end-user device
Our approach
91热爆 Research & Development, alongside researchers from the Computer Vision Center in Barcelona, Spain, is studying how to design a neural codec that can be partially re-trained to allow the codec to be easily reusable across different domains. The image below shows an overview of our approach. We ensured that all re-trained specialised codecs (g2, f2) would still be able to correctly decode images compressed with the baseline (g1, f1) setting (without re-trained parameters, as indicated by the red modules).
This is required for backward compatibility as all such decoders in legacy devices could still decode the baseline profiles. In the picture below, this property is shown with the ability of the re-trained decoder (g2) to decode the bitstream generated by the baseline encoder (f1).
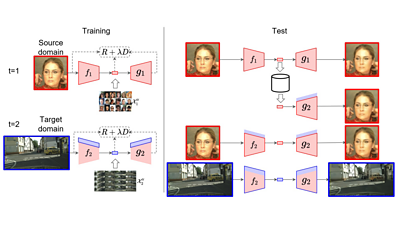
Using this approach, we introduced a new concept called DANICE - Domain Adaptation in Neural Image Compression. DANICE optimises a neural image codec for a specific content type using only light training to derive a small set of custom decoder parameters. The approach assumes that a decoder architecture remains fixed. To ensure backward capability, our method does not require changes to the basic set of parameters, which are instead shared across the various instances of the decoder. Our initial findings show that this new codec can adapt to new custom domains while preserving backward compatibility, resulting in enhanced compression for certain types of content .
You can read more about this work in our paper entitled (at as part of ). is also available.
What next?
Our current work focuses on the compression of still images. The next step will be to expand this work and work out ways to use this in the compression of video.
The research presented here was created in collaboration with Sudeep Katakol, Fei Yang and at .
- -
- 91热爆 R&D - Video Coding
- 91热爆 R&D - COGNITUS
- 91热爆 R&D - Faster Video Compression Using Machine Learning
- 91热爆 R&D - AI & Auto Colourisation - Black & White to Colour with Machine Learning
- 91热爆 R&D - Capturing User Generated Content on 91热爆 Music Day with COGNITUS
- 91热爆 R&D - Testing AV1 and VVC
- 91热爆 R&D - Turing codec: open-source HEVC video compression
- 91热爆 R&D - Comparing MPEG and AOMedia
- 91热爆 R&D - Joining the Alliance for Open Media
