
This is the third of a series of posts on the genesis of and ideas behind our Editorial Algorithms project.
We began with a recollection of how our R&D team observed and learned from editorial expertise around the 91�ȱ� and started wondering whether some of the knowledge needed for curation of content could be translated into automation and technology.
Then in the previous post in this series, Unpicking Web Metadata, we established that publishers provide limited metadata alongside their content, meaning if we wanted to organise web content in ways that would help 91�ȱ� editors, we would need to create our own.
In this third instalment, we look at our attempts at teaching algorithms to understand what content is about, what it is like, and even try and teach them the impossible.
It was not a surprise, but it still was a disappointment: the data typically published alongside web articles would not be particularly useful in our quest to provide editors with ways to quickly assess the relevance, quality and angle of content found around the web. With so little information to work with, short of reading everything yourself, the only quick way to find and curate information from the web would be to use search engines or other third-party tools, which may be quite good at some things but not as flexible or good at others.
Search engines, for instance, have been developed to be very good at finding authoritative content about any topic, but not very good at showing in real time the zeitgeist about that topic. Social media tools are pretty much the opposite, but by their nature and their algorithms they do tend to suffer from blind spots, to create filter bubbles, and more generally there is a lack of transparency about how they pick and sort results that make us, with our public service objective, a little uneasy. If search engine X tells me these are the best resources on topic Y, how can I know why they picked those, what mix of algorithmic choices and commercial interest were involved?
The alternative is not much better. Aggregate a lot of content from sources you know are likely to be relevant in a tool such as a feed reader, scan through the headlines, and read through anything that may be of interest. Such a method works reasonably well, as it makes use of editorial expertise in figuring out what the content is about, what it is like, and how interesting it may be in the editorial context.
It is, however, pretty bad at two things: scaling up, and finding gems outside of the editor’s safe bubble. A headline and a quick scan is enough to intuit whether an article might be relevant, but you still need to read it fully to make sure. This is very time consuming and significantly limits the number of candidates one can consider. And because the selection comes from a limited number of sources, the ability to find a hidden gem from another source is nil.
We thought there may be a better, middle way. Our past research on Natural Language Processing had shown us that modern algorithms could be used fairly effectively to understand what any piece of arbitrary text is about. We had already developed semantic tagging tools to help us extract mentions of people, places, organisations and other concepts from any article.
Could we use this expertise to extract more metadata about length, tone, opinion and all the other qualities we knew were used in making a quick editorial decision when selecting content?
Could we create tools to speed up or even replace the process of scanning for interesting content, leaving the editorial expert to focus on looking through the best candidates, fact-checking them if needed, and using them to tell a story?
Raiding the toolbox
Beyond the ability to tag semantic mentions (eg the mention of an entity such as “Chile” or “Michael Jackson”), the first algorithms we implemented were actually fairly standard ones, and therefore well documented. As a rule of thumb, if an algorithm is fully documented, mathematical formulas and all, in Wikipedia, you can be sure there will be pretty good open source libraries you can use for it.
Having used RSS and Twitter feeds to build a database of automatically updating content, we then set about implementing a few quick-win search features, such as “time to read”, which answered the editorial “is it a long or short read?” question. Likewise, an implementation of the gave us a building block for some of the complex editorial questions we knew we’d want to help automate, such as “is this article in depth?”, “does it provide a summary?” or “is it serious in tone?”. Of course, whether a piece of content is using simple words or convoluted academic vernacular is not a direct measure of depth or seriousness or authority, but our intuition was that it was at least part of the equation.
Some of the qualities we wanted to measure were even fuzzier still, but key: our editorial work established that tone, such as sarcasm and humour, and categories, not simply topics or keywords, were extremely important when an editor came to making decisions on the kind of mix of content they wanted.
Categorising content
Our first big challenge emerged after realising that we needed to categorise the vast number of articles we ingested in a well-defined and structured way. In other words, we needed to sort all the content we were aggregating according to our own taxonomy.
Feeds around the web have the tendency to use a combination of categories and keywords when tagging a published article. Those tags - depending on the feed - can be either present, inconsistent or even completely absent. We also noticed that tags labelling an article often were either too generic like “Europe” or too specific e.g. “Barack Obama”. What we needed was a top-level categorisation that was a) consistent and b) would allow our editors to search for content by filtering/narrowing down easier.
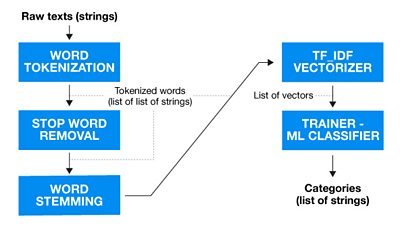
Using machine learning to categorise
In our quest to categorise articles efficiently from a wide variety of different feeds, we used a Machine Learning (ML) model that tracked word and co-word occurrences. First we identified a taxonomy that would cover all the areas our editors required. Then we manually curated a diverse training dataset for all 20 categories, around 25 articles for each, from which we derived a list of word occurrences and co-occurrences. The model could then check any new article against this list, and identify which category it fit into based on the words it used.
Our final step included training several machine learning models to compare their accuracies and precision by a stratified 10-fold cross validation procedure. That allowed us to extract homogeneous subgroups and validate our models’ efficiency and of course derive which model performed the best.
We tried models such as ‘decision trees’, ‘random forests’, ‘nearest neighbours’, but ‘linear support vector classification’ and ‘logistic regression’ outperformed all of them. Eventually we chose ‘logistic regression’ as it handled multi-class classification nicely and returned helpful probability estimates for each class, a fact that could allow us to return multiple categories for an article when the certainty of it belonging to only one category was not high enough.
Getting the most out of linguistic features
After getting accurate results and classifying articles based on our taxonomy, we went on to tackle the issue of tone, which our early research had identified was a vital consideration for content editors.
The category of an article was not enough to determine the tone of an article, ie whether it took its topic seriously or lightly. Category relates to the topic of an article only, but it is entirely possible to find a funny article on a series topic, and vice versa. That made us wonder whether we could manually create a dataset of serious and light content, label it one or the other, and then automatically judge unseen articles based on their stemmed word and co-word occurrences.
What we needed to prove here is that linguistic features of an article’s main content can give us enough in order to define its tone. In order to investigate that we groundtruthed and gathered a dataset manually, determining an article’s tone on a scale from zero to one, one being the most serious-toned article.
Again we turned our word and co-word occurrences into vectors and drew a plane that based on our training dataset would try to separate any previously unseen articles to serious and light. The ‘logistic regression’ model once again performed best and our results showed that on average we could accurately classify 83% of cases. Our first iteration yielded approximately 76% accuracy. By adding more articles we reached 83%, a number that indicates there’s potential for even more improvement.
Classifying linguistic features (a.k.a “the problem with sarcasm”)
Tone or sentiment are both famously difficult for a computer to identify. Even more tricky is sarcasm, but we like a challenge. We wondered if we could analyse a sample sentence (most likely the title of an article that holds the highest amount of information about it) and, by training an ML model, distinguish sarcastic and no-sarcastic sentences.
The tricky part here is that sarcasm does not have a specific vocabulary that could unravel its existence within a piece of text. Sure, there are a couple of indicators we could rely on - whether those indicators are linguistic or not - but there are so many dependencies on metadata that are not universally present and/or consistent. For instance, an article’s author could be one of those factors, but as our research revealed the presence of this information in the metadata cannot be taken for granted. Other factors included the context an entity or a topic is mentioned within, recent events and so on.
We took two approaches:
- We trained the model on sarcastic sentences selected by our editorial team in the hope we could approximately capture a sarcasm-related vocabulary.
- We constructed features per sentence using its tone, sentiment, entities mentioned, publishing source, specific words presence and their position within the sentence and so on.
Both techniques showed potential but unfortunately neither yielded concrete evidence that we could build a model that would accurately capture sarcasm in text. Quelle surprise.
Getting the most out of semantic tagging
Setting machine learning techniques aside, we also looked into algorithms that would take advantage of the already extracted metadata we could provide useful insights on an article.
Using Mango, our automated semantic tagging service, we can accurately extract topics and entities (ie people, places and organisations) mentioned in a piece of text, as well as disambiguate between words or phrases that could refer to similar concepts in terms of language.
Semantic tagging, however, is only good at answering the question “what things are mentioned in this text”, but falls short of answering the much harder question of “what is this piece of text actually about?”. For an algorithm, this question can be hard, very hard, or fiendishly hard to answer.
In some cases, the “thing about which the text is essentially about” (which, for short, we typically call the main protagonist) is actually mentioned in the text itself. Finding the main protagonist then becomes an exercise in finding which of the extracted entities is the most relevant (and thus the most likely protagonist candidate).
We explored different algorithms, essentially scoring the entities’ relevance by looking at their positioning and repetition, and tested a few variants where the candidate protagonist would be selected solely amongst people, or from the full list of extracted concepts. Results have been promising, but of course this method does not help with the harder case of a piece of text where the main protagonist is only hinted at, or where an inferred concept (for example, “pop music” in an article about various artists in the charts) would be a more accurate description of “what is this piece of text about”.
This work also provided inspiration for another of our projects, which, in a way, looks at the reverse question: given a very fuzzy “topic” for which the boundaries cannot be expressed clearly, how well can Machine Learning algorithms be trained to recognise content relevant (and not relevant) to that topic? But we shall leave that for another blog post.
Next in this series: we will start looking at applications of the metadata our algorithms created. Given our ability to derive knowledge about what content is about (with semantic tagging and categorisation) and what it is like (with tone detection and sentiment analysis), can we actually create tools to complement, speed up or even replace the “gut feeling” of a well trained curator?
-

Internet Research and Future Services section
The Internet Research and Future Services section is an interdisciplinary team of researchers, technologists, designers, and data scientists who carry out original research to solve problems for the 91�ȱ�. Our work focuses on the intersection of audience needs and public service values, with digital media and machine learning. We develop research insights, prototypes and systems using experimental approaches and emerging technologies.